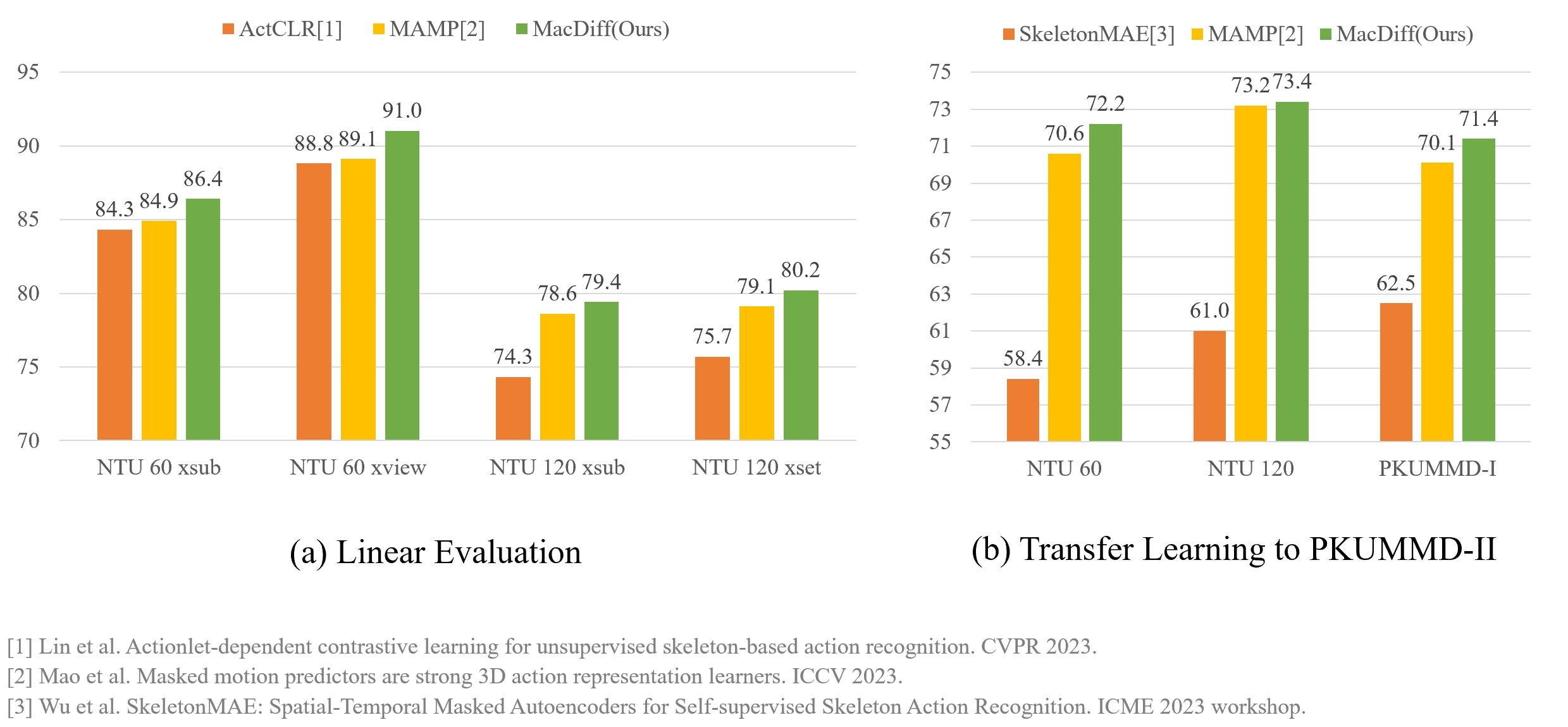
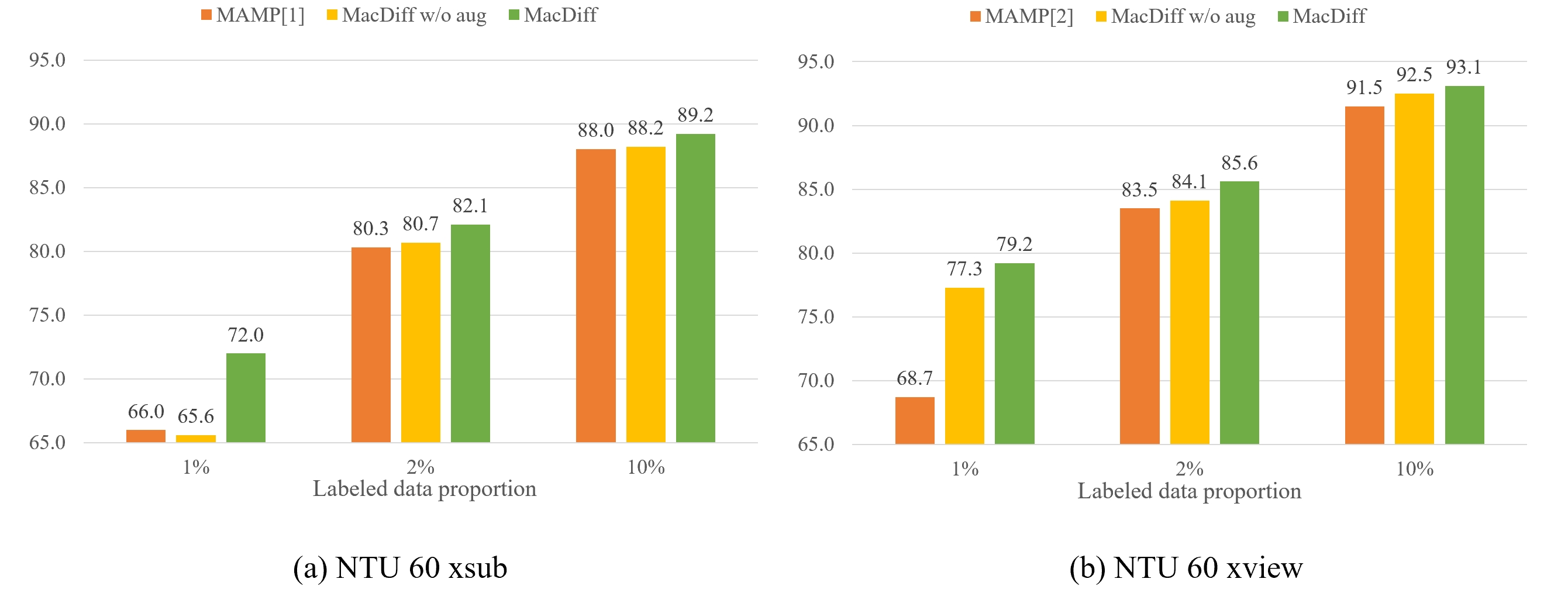
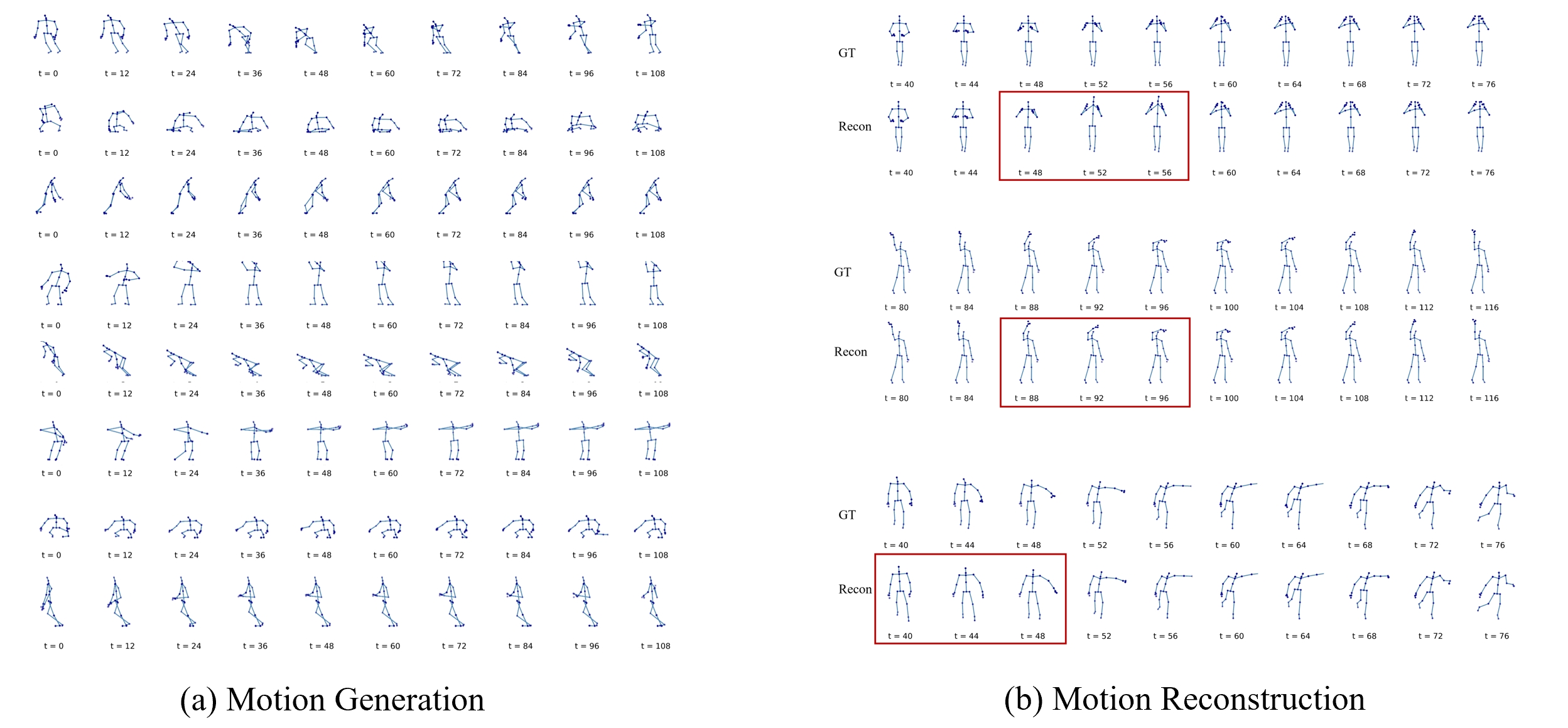
Method
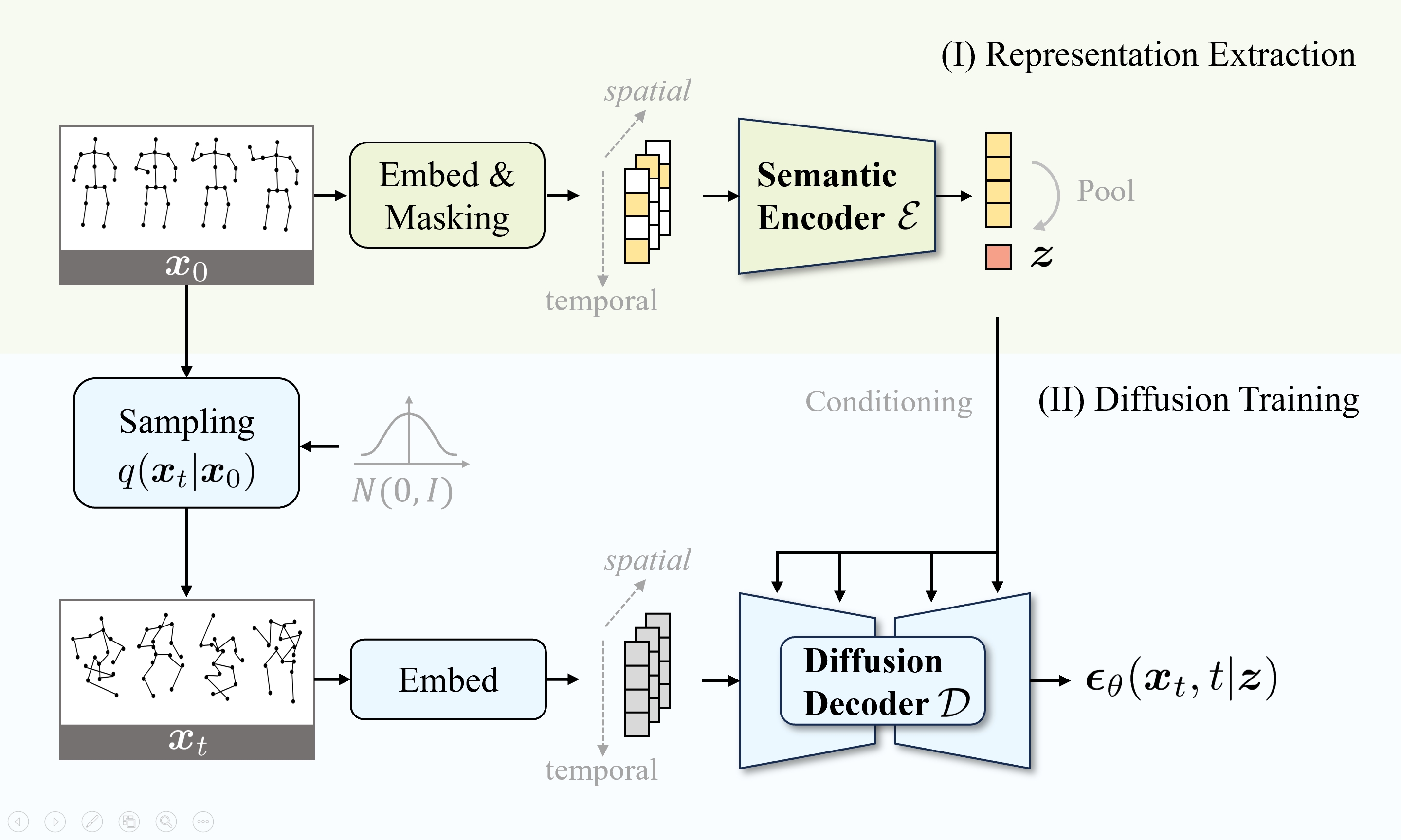
We train a diffusion decoder conditioned on the representations extracted by a semantic encoder.
(I) We embed skeletons into tokens and employ random masking. The global representation
is obtained by pooling the local representations extracted by the semantic encoder.
(II) We sample the noisy skeleton following the diffusion process $q(x_t|x_0)$. The diffusion decoder predicts the noise $\epsilon$
from $x_0$ guided by the learned representation $z$. The pre-trained encoder can be utilized independently in downstream discriminative tasks.